字节跳动开源 Lance:3B 参数统一图像视频理解生成与编辑
字节跳动发布 Lance,一个仅 3B 激活参数的轻量级原生统一多模态模型,在单一框架下同时支持图像理解、视频理解、图像生成、视频生成和跨模态编辑五种任务。模型使用 Apache 2.0 许可,权重已在 Hugging Face 开放。

架构设计:共享上下文 + 双流专家
Lance 采用共享交织多模态序列(shared interleaved multimodal sequence)作为统一上下文表示,使文本、图像和视频在同一个序列空间中交互学习。同时引入双流混合专家架构(dual-stream MoE),将语义理解和视觉生成的能力路径解耦:
- 理解流:基于 Qwen2.5-VL 编码器,负责视觉问答、图像/视频描述等语义任务
- 生成流:基于 Wan2.2 编码器,负责文本生成图像/视频、跨模态编辑等合成任务
为解决不同模态视觉 token 在统一序列中的位置干扰问题,Lance 提出模态感知位置编码(MaPE,Modality-aware Rotary Positional Encoding),根据 token 的模态类型(语义 ViT token、干净 VAE latent、带噪 VAE latent 等)调整位置编码,减少跨任务干扰。
训练方案
Lance 从零训练(除 ViT 和 VAE 编码器外,Transformer backbone 完全从头训练),训练预算为 128 张 A100 GPU。采用分阶段多任务训练范式,将理解、生成和编辑任务统一到同一任务框架中,配合能力导向的目标函数和自适应数据调度策略,逐步增强语义理解和视觉合成能力。
基准测试表现
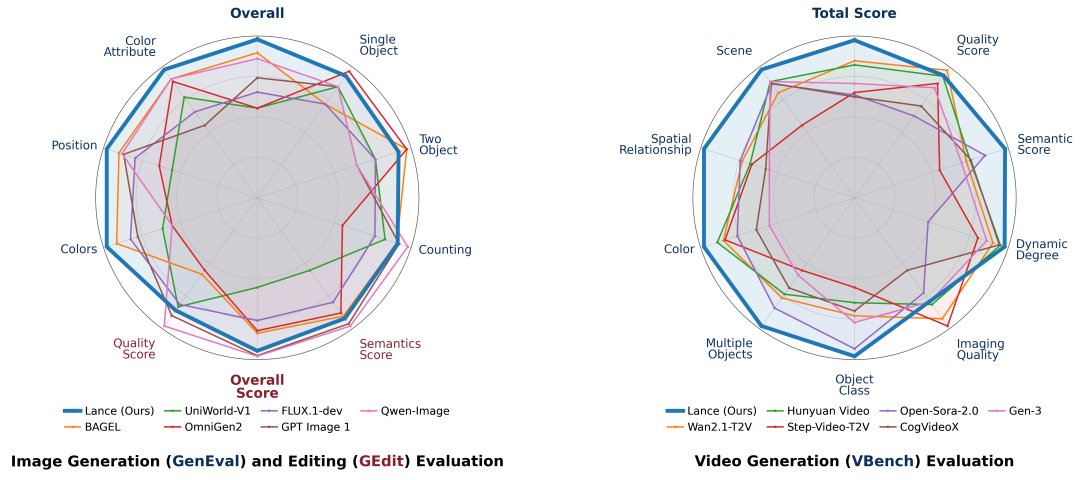
在多个基准上,Lance 以 3B 参数量超越或追平更大规模的统一模型:
- GenEval(图像生成):与 7B/13B 模型持平或领先,在关系定位和空间一致性维度表现突出
- DPG-Bench(图像生成):在关系类提示词理解上达到 93.38 分
- GEdit-Bench(图像编辑):统一模型中平均得分最佳
- VBench(视频生成):总分 85.11,为统一模型最高,在视觉质量、色彩一致性、场景理解等维度全面领先
- MVBench(视频理解):统一模型中平均得分最佳

适用任务
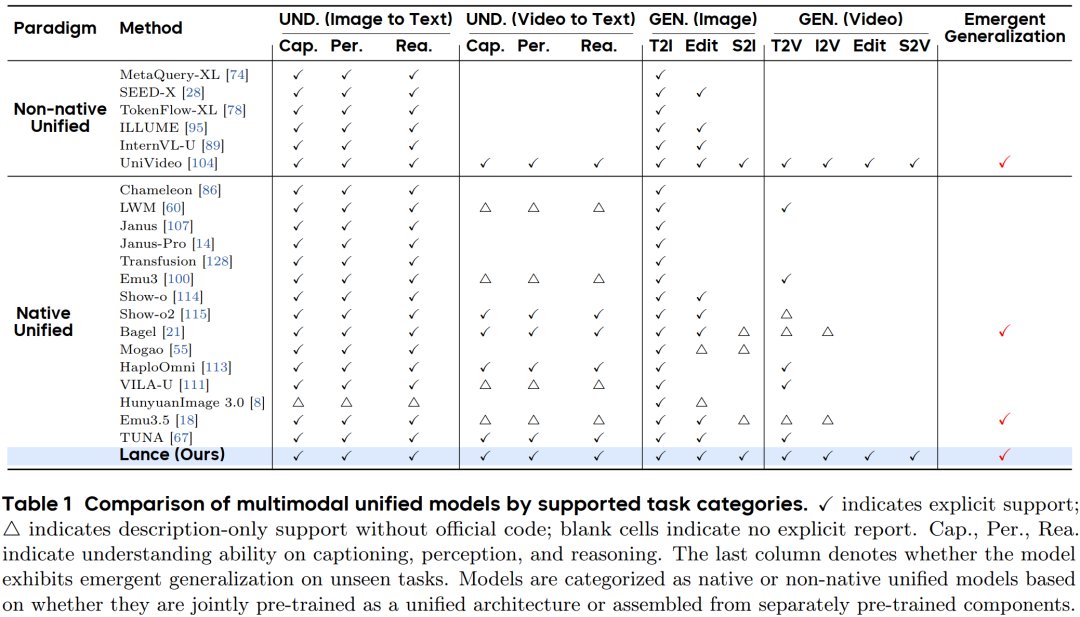
Lance 提供统一的命令行接口,支持六种任务:
- 文本生成图像(t2i)
- 文本生成视频(t2v),最多支持 121 帧
- 图像编辑(image_edit)
- 视频编辑(video_edit)
- 图像理解(x2t_image)
- 视频理解(x2t_video)
单 GPU 即可运行推理,推荐 30 步去噪,CFG scale 4.0。
下载与试用
模型权重、推理脚本和论文链接:
- GitHub:https://github.com/bytedance/Lance
- Hugging Face:https://huggingface.co/bytedance-research/Lance
- 论文:arXiv 2605.18678
来源:字节跳动开源 · GitHub · arXiv
相关推荐
- ChatGPT App 的模型切换入口,突然变得很难找3/17/2026
- 据路透:华虹旗下华力微电子拟量产 7 纳米,华虹或成中国第二家 7nm 代工厂3/16/2026
- Anthropic 超 8 万用户调研:81% 认为 AI 正兑现预期3/19/2026
- Google 把 Stitch 升级成 AI 原生设计画布3/19/2026
- DLSS 5 引发的争议:老黄说批评者完全错误3/19/2026
- 小米三款大模型齐发:MiMo-V2-Pro、Omni、TTS 完整解读3/19/2026
- 椰树集团相关公司招标 50 台人形机器人剥椰子,产线开始提具体指标了3/19/2026
- Firefox 149 内置免费 VPN:50GB 月流量,首批限四国3/19/2026
- Hugging Face 最大开源仓库快被 AI 垃圾 PR 淹没了3/19/2026
- 营收涨三倍,宇树科技冲刺科创板3/20/2026
- Google AI Studio 升级全栈 vibe coding:Antigravity 代理来了3/20/2026
- OpenAI 收购 Astral:Python 工具链收编加速3/19/2026
- 多地试点一人公司:免费公寓+办公空间,能否激活个体创新?3/19/2026
- 谷歌 Gemini Mac 版内测:桌面端补课正式开始3/20/2026
- Kimi 员工指称 MiniMax 沿用其 Office Skill 代码始末3/19/2026
- 苹果把 WWDC 2026 定在 6 月 8 日,AI 与开发者工具会是重点3/23/2026
- 爱泼斯坦案幸存者起诉 Google:AI 搜索放大了数据泄露的伤害3/27/2026
- iOS 26.4 RC 发布:Apple Music 有 AI 歌单,Podcasts 支持视频3/18/2026
- 欧盟推去衣AI禁令:3月26日表决,执法难在哪3/19/2026
- 短视频内容标注,准备进入统一规则阶段3/21/2026
- 小米推理模型 MiMo-V2-Pro 上线:智能指数 49,榜单排第 103/18/2026
- MiniMax 发布 M2.7:国内首个公开的模型自我进化方案3/18/2026
- 英伟达把 DLSS 5 说清楚了:输入只有 2D 帧和运动矢量3/21/2026
- 中国加大对 Meta 收购 Manus 审查:高管限制离境,审查升至国家层面3/18/2026
- Google 测试改写搜索结果网页标题,网站对标题的控制权又退了一步3/20/2026
- 《华盛顿邮报》把 AI 用到订阅定价上,媒体的个性化收费又往前走了一步3/17/2026
- Claude Code 上线 Channels:用 Telegram 和 Discord 操控本地编程任务3/20/2026
- 鸿海 Q4 利润不及预期,给 AI 硬件热泼了一盆冷水3/16/2026
- OpenAI 发布 GPT-5.4 mini 与 nano:小模型加速冲刺3/17/2026
- 据报道,微软搁置 Windows 11 多项 Copilot 系统级整合计划3/16/2026