NIST 下属人工智能标准与创新中心(CAISI)发布了对 DeepSeek V4 Pro 的评估报告。结论:DeepSeek V4 Pro 是 CAISI 迄今评估的最强中国 AI 模型,但综合能力比美国前沿模型落后约 8 个月。
核心结论
CAISI 使用了受项目反应理论(IRT)启发的聚合评估方法,在网络安全、软件工程、自然科学、抽象推理和数学五个领域共 9 个基准上测试了模型。DeepSeek V4 Pro 的 IRT-Estimated Elo 得分为 800,与 GPT-5(约 8 个月前发布)水平相当。

DeepSeek 自报 vs CAISI 评测的差异
DeepSeek 官方技术报告称 V4 Pro 与 Opus 4.6 和 GPT-5.4(约 2 个月前发布)能力相当。但 CAISI 的评估包含了非公开基准,结果显示 DeepSeek V4 Pro 实际表现更接近 GPT-5 的水平。
差距主要体现在代理任务和推理类测试上:
- ARC-AGI-2 半私有数据集:GPT-5.5 得分 79%,Opus 4.6 得分 63%,DeepSeek V4 Pro 仅 46%
- PortBench(CAISI 自建软件工程评估):GPT-5.5 得分 78%,Opus 4.6 得分 60%,DeepSeek V4 Pro 仅 44%
- CTF-Archive-Diamond(网络安全):GPT-5.5 得分 71%,Opus 4.6 得分 46%,DeepSeek V4 Pro 仅 32%
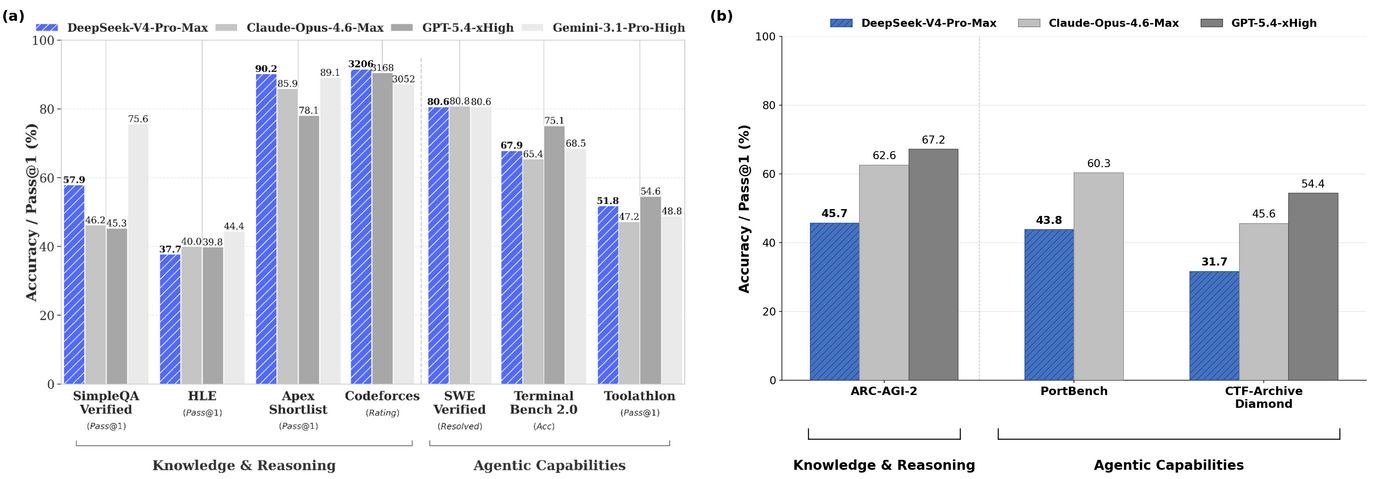
但在传统知识问答和数学方面差距较小:
- GPQA-Diamond:DeepSeek 90% vs GPT-5.5 96%
- FrontierScience:DeepSeek 74% vs GPT-5.5 79%
- SWE-Bench Verified:DeepSeek 74% vs GPT-5.5 81%
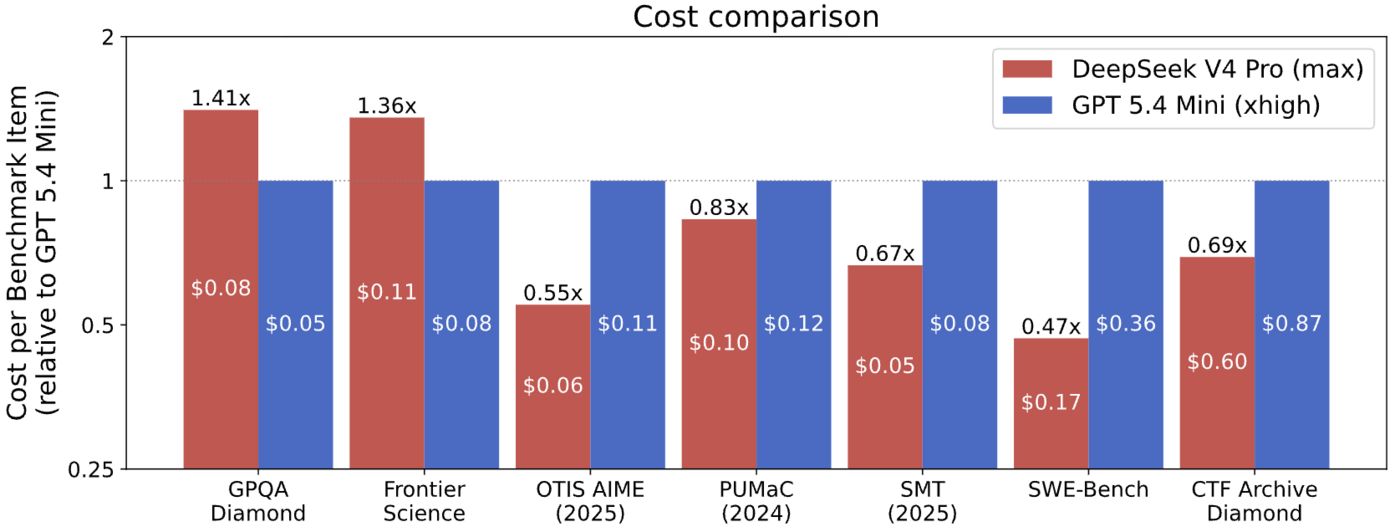
成本效率
CAISI 选取 GPT-5.4 mini(Elo 749,与 DeepSeek V4 Pro 的 800 相近)作为成本对比参照。结果:
- DeepSeek V4 Pro 在 7 个基准中的 5 个上成本更低
- 成本优势从便宜 53% 到贵 41% 不等
评估方法说明
CAISI 使用 IRT 方法将 AI 模型比作"学生",将单个基准任务比作"考题",通过聚合分析得出每个模型在所有基准上的相对能力水平。Figure 1 的趋势线覆盖了 16 个基准、35 个模型的数据,每 200 分 Elo 对应解决任务的胜率提升 3 倍。
来源:NIST/CAISI