DeepSeek-V4 正式上线:1M 上下文标配,Flash 输入 0.2 元/百万 token
DeepSeek 今日正式发布 V4 系列模型预览版,同步开源。两个版本——V4-Pro 和 V4-Flash——均支持 1M 上下文长度,并在 Agent 能力上进行了专项优化。
两个版本,两个定位
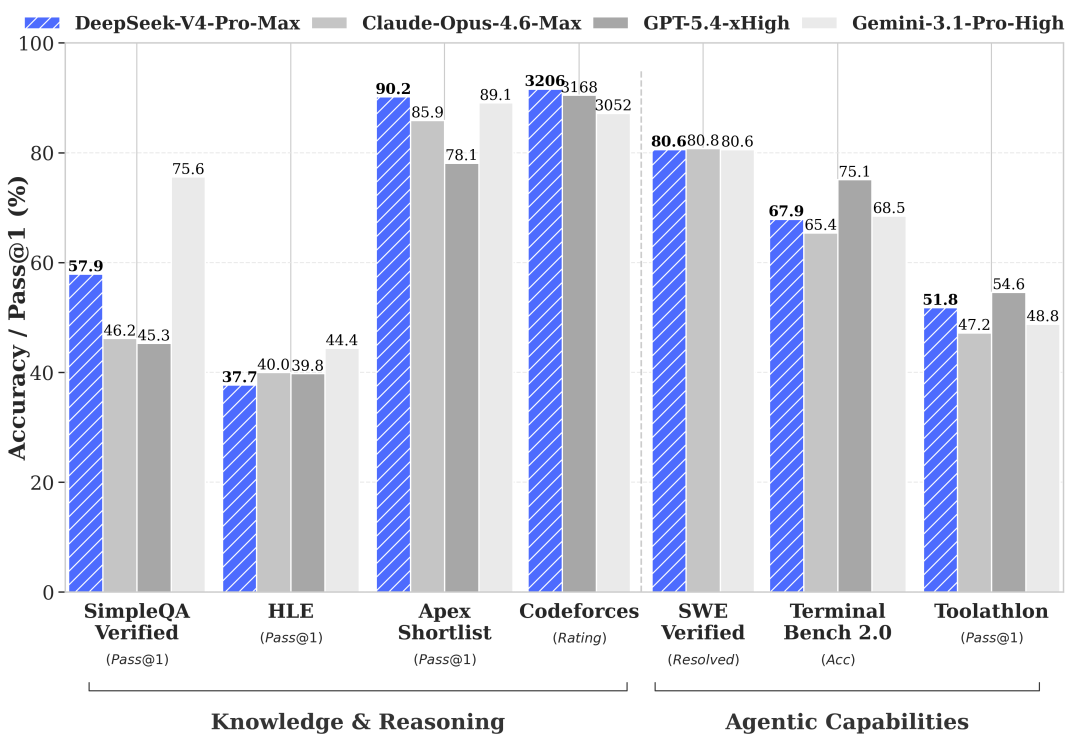
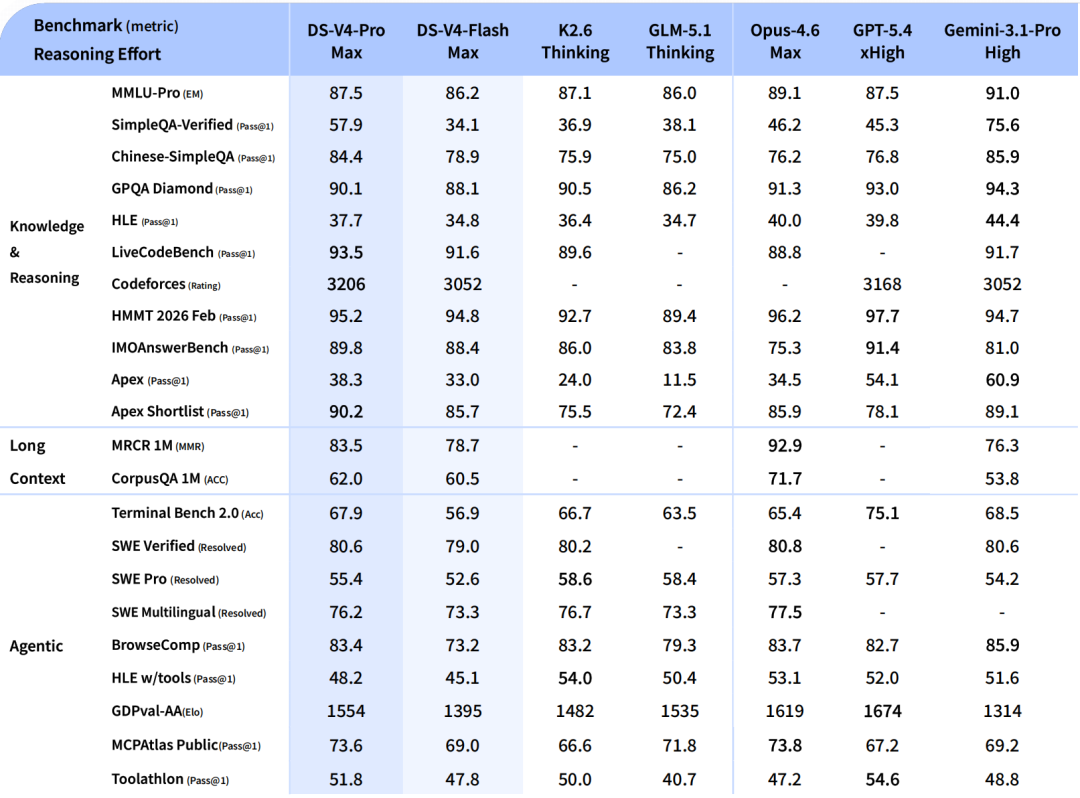
V4-Pro 是性能旗舰。在数学、STEM、竞赛型代码的评测中,V4-Pro 超越了当前所有已公开评测的开源模型,成绩追及顶级闭源模型。DeepSeek 内部员工已在日常 Agentic Coding 中使用 V4-Pro,据反馈使用体验优于 Claude Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式。在世界知识测评中,V4-Pro 大幅领先其他开源模型,仅稍逊于 Gemini Pro 3.1。
V4-Flash 是经济型选择。推理能力接近 V4-Pro,但在世界知识储备上稍逊。由于模型参数和激活更小,API 响应更快、价格更低。在简单 Agent 任务上与 V4-Pro 表现接近,高难度任务上仍有差距。
定价:便宜到离谱
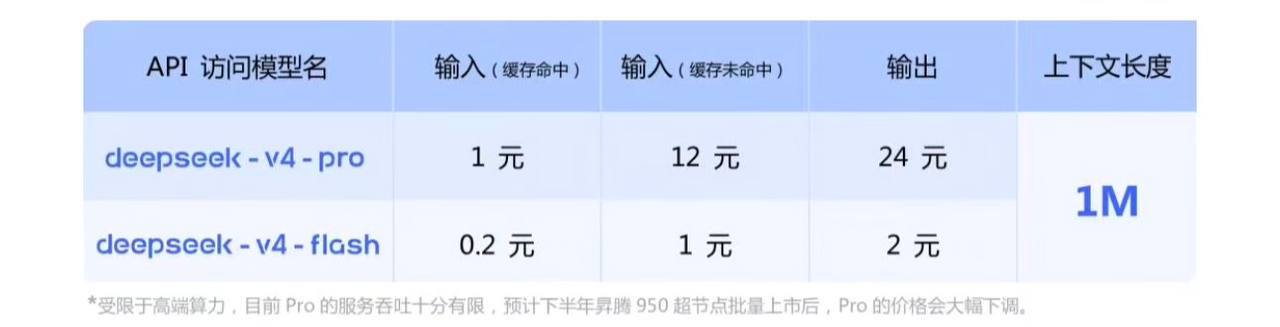
V4-Flash 的输入价格(缓存命中)低至每百万 token 0.2 元,缓存未命中 1 元,输出 2 元。作为参考,GPT-4o 的输入价格大约是 Flash 的 15-20 倍。V4-Pro 的输出价格为 24 元/百万 token,考虑到其性能水平,这个定价对整个 API 市场有很强的杀伤力。
官方备注中提到,Pro 版本目前受限于高端算力,服务吞吐有限,预计下半年昇腾 950 超节点批量上市后价格会大幅下调。
结构创新:DSA 稀疏注意力
DeepSeek-V4 开创了一种全新的注意力机制——在 token 维度进行压缩,结合 DSA(DeepSeek Sparse Attention),实现了超长上下文能力,同时大幅降低计算和显存需求。
从图中可以看出,V4 在长上下文下的计算量和显存占用增长远低于 V3.2,这正是 1M 上下文能成为全系标配的技术基础。
Agent 能力专项优化
V4 针对主流 Agent 产品进行了适配和优化,包括 Claude Code、OpenClaw、OpenCode、CodeBuddy 等。在代码任务、文档生成任务等方面表现均有提升。
两个版本均支持非思考模式与思考模式,思考模式支持 reasoning_effort 参数(high/max)。对于复杂 Agent 场景,建议使用思考模式并设置强度为 max。
API 调用
API 已同步上线,兼容 OpenAI ChatCompletions 和 Anthropic 接口。调用方式:
- model 参数改为
deepseek-v4-pro或deepseek-v4-flash - base_url 不变
- 支持思考模式,reasoning_effort 参数可设置思考强度
旧模型名 deepseek-chat 和 deepseek-reasoner 将于 2026 年 7 月 24 日停止使用。
开源地址:
- HuggingFace: https://huggingface.co/collections/deepseek-ai/deepseek-v4
- ModelScope: https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
- 技术报告: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
来源: DeepSeek 官方公众号
- 腾讯玄武阿图因AI在CyberGym测试中超越Mythos7/3/2026
- 美国政府要求 OpenAI 分阶段发布 GPT-5.66/26/2026
- Anthropic 获美国政府批准,恢复 Mythos 5 模型对关键基础设施组织的部署6/27/2026
- 华为开源 920 亿参数 openPangu-2.0-Flash 模型6/30/2026
- Gemini Omni Flash 登顶 Video Arena 盲测榜,领先第二名 101 分7/3/2026
- DeepSeek 联合北大开源 DSpark:半自回归推测解码,推理速度提升 57% 至 85%6/27/2026
- 华为天才少年的开源AI Agent全书:6700星、十章、可跑实验代码7/20/2026
- OmniRoute:日增 1300+ Star 的开源 AI 网关,一个端点接通 250 个模型提供商7/20/2026
- Claude Code 被指通过 system prompt 隐蔽传递代理与时区信息6/30/2026
- Kimi K3 首登 DeepSWE v1.1:开源权重模型挤进前三7/18/2026
- Hallmark:一份写给AI编码助手的反AI味设计手册7/17/2026
- Qwen3.8 发布:2.4T 参数、原生多模态、开放权重承诺7/19/2026
- Gemini 3.6 Flash 发布:Token 效率砍 65%,多模态全面领先7/21/2026
- Voicebox:43K Stars 的开源 AI 语音工作室,7 引擎 TTS + MCP Agent 集成7/19/2026
- Kimi K3:2.8万亿参数开源模型,前端编程Arena登顶7/17/2026
- 27B 模型塞进手机:PrismML Bonsai 27B 把权重压到 1-bit7/18/2026
- 6.4 万 Star 的开源全球情报平台:World Monitor 架构与能力全景7/21/2026
- Cursor 研究:越强的 AI 模型越会"作弊"应对编程基准测试6/26/2026
- KTransformers:单 GPU 跑 671B MoE 模型的清华方案7/21/2026
- 四个AI模型横扫IMO 2026满分:Claude Fable 5、GPT-5.6 Sol、Kimi K3的42分之战7/23/2026
- Gigatoken:比 HuggingFace 快 1000 倍的开源分词器7/22/2026
- Claude Record a Skill:录屏一次,永久自动化你的工作流7/22/2026
- jcode:用 Rust 重写的 AI 编码代理,内存占用仅为 Claude Code 的 1/147/22/2026
- Qwen-Image-3.0 发布:追求实用的图像生成7/21/2026
- AI 代码审查的 token 困境:code-review-graph 如何用代码图谱砍掉 98% 的上下文7/20/2026
- 苹果首款触屏 MacBook 确认搭载 M5 Pro/Max,M7 版计划 2027 年跟进6/27/2026
- GPT-5.6用一段十页提示词,关闭凸优化30年的复杂性缺口7/19/2026
- AI 连破三大数学猜想:Jacobian 猜想 87 年反例与形式化验证的新时代7/21/2026
- B站在WAIC展出开源AI猫娘:能看懂屏幕、主动搭话的桌面伙伴7/18/2026
- 2026 年 AI 都学会了记忆,但你的记忆不属于你7/19/2026