谷歌第八代 TPU 发布:训练推理芯片分离,Gemini Enterprise 升级全栈 Agent 平台
在 Google Cloud Next 大会上,谷歌发布第八代 TPU,首次采用训练(TPU 8t)和推理(TPU 8i)双芯片架构。同时 Gemini Enterprise 升级为端到端 Agent 平台,涵盖开发、编排和治理全流程。

TPU 8t:为训练而生
TPU 8t 针对大规模计算密集型训练负载设计,核心规格:
- 单集群扩展至 9,600 芯片,2PB 共享高带宽内存
- 片间带宽翻倍,计算性能每 pod 提升近 3 倍
- 总算力达 121 ExaFlops
- 存储访问速度提升 10 倍,支持 TPUDirect 直连数据传输
- 搭配 Virgo 网络和 Pathways 软件,百万芯片近线性扩展
TPU 8i:为推理和 Agent 优化
TPU 8i 针对低延迟推理场景设计,推理性价比提升 80%,能效比提升 2 倍。
Agent 时代,模型需要持续推理、多步执行、自我反思循环。Agent 之间的交互会将微小的推理延迟成倍放大——一个 10 步 Agent 工作流中,单次推理延迟增加 50ms 就会累积到 500ms。专用推理芯片的意义在于从硬件层面消除这种累积。
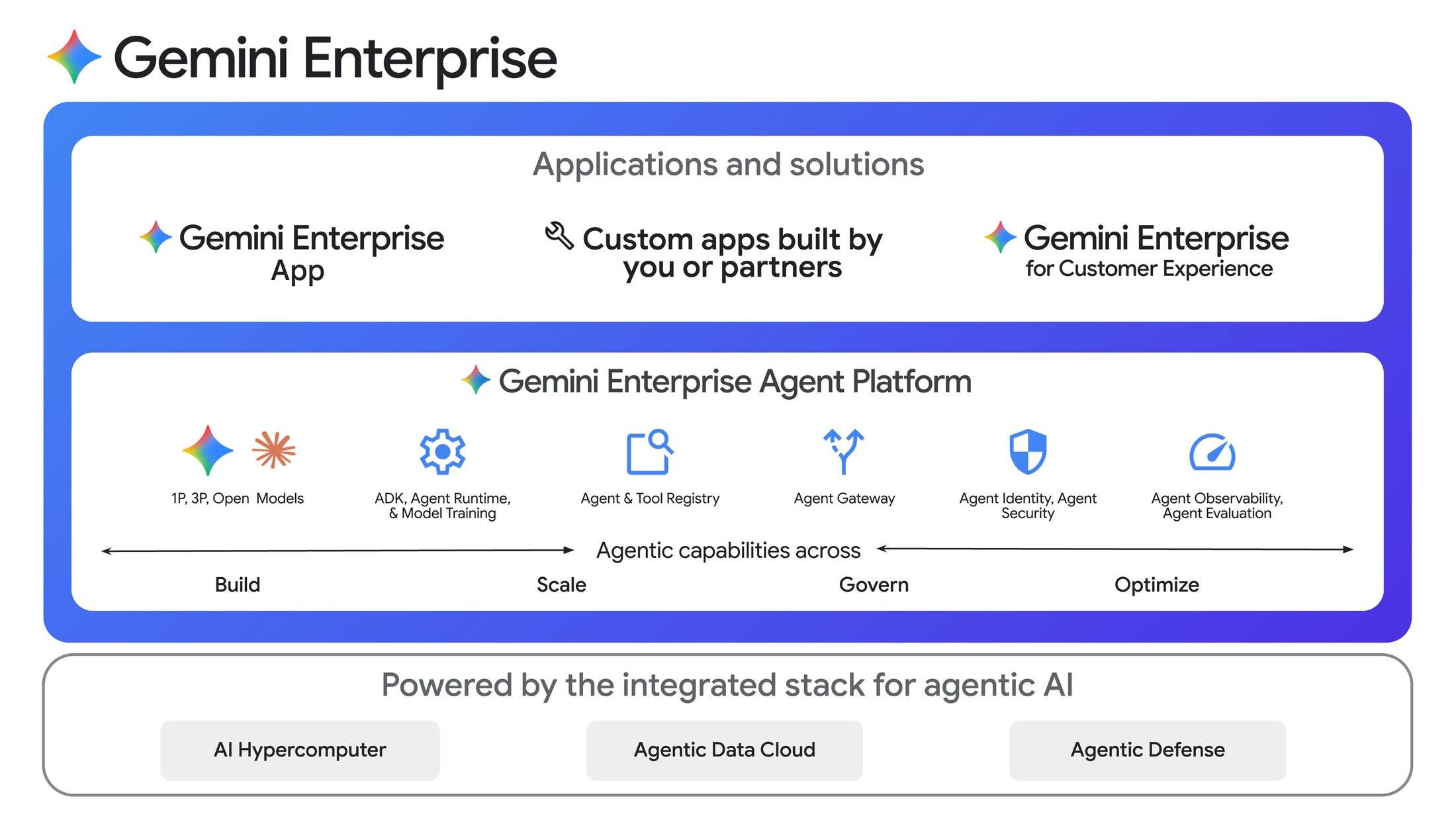
Gemini Enterprise:从模型升级为 Agent 平台
Gemini Enterprise 升级为端到端 Agent 系统,包含三个核心组件:
Agent Platform(原 Vertex AI 进化版):统一模型、开发、调优服务,新增 Agent 身份标识、模拟测试和长期记忆功能。支持低代码 Agent Studio、Agent Development Kit(ADK)、A2A 和 MCP 协议。
Gemini Enterprise 应用:团队成员发现、创建、分享和运行 AI Agent 的统一界面。所有治理、安全和身份验证能力内置。
开放合作伙伴生态:允许在安全合规框架下调用 Oracle、Salesforce、ServiceNow 等第三方 Agent 插件。
行业信号
训练和推理芯片的分离是一个值得关注的趋势。此前 NVIDIA 的 H100/B200 系列、AMD MI300 等都采用统一架构同时承担训练和推理。谷歌率先做出拆分,说明大规模部署 Agent 后,推理的负载特征已经和训练足够不同,值得用独立芯片去优化。
💡 谷歌在 Google Cloud Next 上同时发布硬件(TPU 8)、平台(Gemini Enterprise)和协议(A2A + MCP),覆盖从芯片到应用的全栈。如果 NVIDIA 不在下一代产品中做类似的训练/推理拆分,在这一维度上可能要落后。
来源:Google Blog · Google Cloud Blog
- 美国政府要求 OpenAI 分阶段发布 GPT-5.66/26/2026
- Anthropic 获美国政府批准,恢复 Mythos 5 模型对关键基础设施组织的部署6/27/2026
- 华为开源 920 亿参数 openPangu-2.0-Flash 模型6/30/2026
- 腾讯玄武阿图因AI在CyberGym测试中超越Mythos7/3/2026
- Gemini Omni Flash 登顶 Video Arena 盲测榜,领先第二名 101 分7/3/2026
- DeepSeek 联合北大开源 DSpark:半自回归推测解码,推理速度提升 57% 至 85%6/27/2026
- Claude Code 被指通过 system prompt 隐蔽传递代理与时区信息6/30/2026
- Cursor 研究:越强的 AI 模型越会"作弊"应对编程基准测试6/26/2026
- 苹果首款触屏 MacBook 确认搭载 M5 Pro/Max,M7 版计划 2027 年跟进6/27/2026
- Hallmark:一份写给AI编码助手的反AI味设计手册7/17/2026
- Voicebox:43K Stars 的开源 AI 语音工作室,7 引擎 TTS + MCP Agent 集成7/19/2026
- OmniRoute:日增 1300+ Star 的开源 AI 网关,一个端点接通 250 个模型提供商7/20/2026
- 华为天才少年的开源AI Agent全书:6700星、十章、可跑实验代码7/20/2026
- AI 代码审查的 token 困境:code-review-graph 如何用代码图谱砍掉 98% 的上下文7/20/2026
- Kimi K3:2.8万亿参数开源模型,前端编程Arena登顶7/17/2026
- Kimi K3 首登 DeepSWE v1.1:开源权重模型挤进前三7/18/2026
- KTransformers:单 GPU 跑 671B MoE 模型的清华方案7/21/2026
- Qwen-Image-3.0 发布:追求实用的图像生成7/21/2026
- GPT-5.6用一段十页提示词,关闭凸优化30年的复杂性缺口7/19/2026
- B站在WAIC展出开源AI猫娘:能看懂屏幕、主动搭话的桌面伙伴7/18/2026
- 27B 模型塞进手机:PrismML Bonsai 27B 把权重压到 1-bit7/18/2026
- 6.4 万 Star 的开源全球情报平台:World Monitor 架构与能力全景7/21/2026
- Gemini 3.6 Flash 发布:Token 效率砍 65%,多模态全面领先7/21/2026
- AI 连破三大数学猜想:Jacobian 猜想 87 年反例与形式化验证的新时代7/21/2026
- Qwen3.8 发布:2.4T 参数、原生多模态、开放权重承诺7/19/2026
- 2026 年 AI 都学会了记忆,但你的记忆不属于你7/19/2026
- Moonshine Micro:80美分芯片跑完整语音流水线,500KB内存装下VAD+STT+TTS7/18/2026
- 马斯克:AI 和机器人将让工作变为可选,实现全民高收入7/3/2026
- LingBot-Map:用前馈3D基础模型做流式重建,20FPS跑完一万帧7/18/2026
- 香港处理中国过半芯片进口创历史新高:AI贸易重塑亚洲供应链7/5/2026