Qwen3.6-27B 开源发布,27B 稠密模型编程能力全面超越前代 397B 旗舰
阿里通义千问团队发布 Qwen3.6-27B,一个 270 亿参数的稠密多模态模型。仅凭 27B 参数,在所有主要编程基准上全面超越上一代开源旗舰 Qwen3.5-397B-A17B(3970 亿参数 MoE,170 亿激活)。

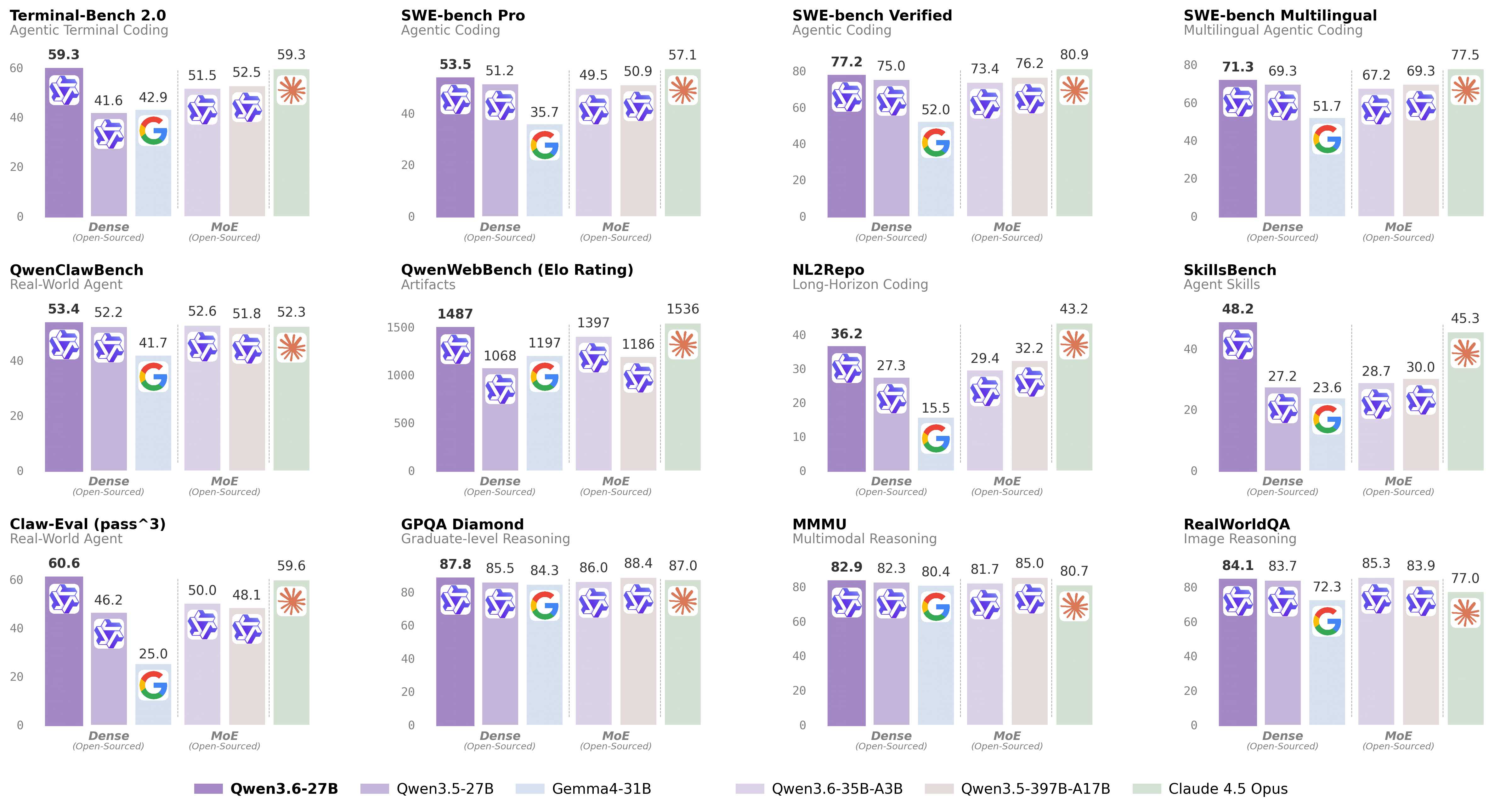
编程能力:Agent 实操提升最显著
Qwen3.6-27B 与前代旗舰的对比数据:
| 基准 | Qwen3.6-27B | Qwen3.5-397B-A17B | 差距 |
|---|---|---|---|
| SWE-bench Verified | 77.2 | 76.2 | +1.0 |
| SWE-bench Pro | 53.5 | 50.9 | +2.6 |
| Terminal-Bench 2.0 | 59.3 | 52.5 | +6.8 |
| SkillsBench | 48.2 | 30.0 | +18.2 (+60%) |
| Claw-Eval Pass³ | 60.6 | 48.1 | +12.5 |
| QwenWebBench (Elo) | 1487 | 1186 | +301 |
SkillsBench 提升幅度达到 60%,SWE-bench Pro 和 Claw-Eval Pass³ 的提升也非常显著。这说明 Qwen3.6-27B 的进步集中在 Agent 实操能力上——写代码、改 Bug、完成真实项目任务。
稠密架构的部署优势
MoE 架构虽然能控制激活参数量,但路由逻辑增加了部署和推理的复杂性。27B 稠密模型规避了这个问题——一张 24GB 显卡就能跑,部署方式简单直接。
对需要本地部署编程助手的开发者来说,这个模型会成为社区实际使用率最高的编程模型之一。结合 OpenClaw、Claude Code 等编程助手的开源生态,硬件门槛大幅降低。
与闭源模型的差距
Claude 4.5 Opus 在所有编程基准上仍然全面领先。SWE-bench Verified 上 Opus 80.9 vs Qwen3.6-27B 77.2,差距约 3.7 个百分点。但相比上一代,开源模型和闭源顶级的差距在逐步缩小。
在推理任务(GPQA Diamond 87.8、MMMU 82.9)上,Qwen3.6-27B 也保持了与更大模型的竞争力,多模态推理能力同样在线。
💡 一个 27B 稠密模型在编程 Agent 任务上全面超越 15 倍参数量的前代旗舰,开源 AI 的进步速度正在加快。
来源:Qwen 官方博客
推荐阅读
- 美国政府要求 OpenAI 分阶段发布 GPT-5.66/26/2026
- Anthropic 获美国政府批准,恢复 Mythos 5 模型对关键基础设施组织的部署6/27/2026
- 华为开源 920 亿参数 openPangu-2.0-Flash 模型6/30/2026
- 腾讯玄武阿图因AI在CyberGym测试中超越Mythos7/3/2026
- Gemini Omni Flash 登顶 Video Arena 盲测榜,领先第二名 101 分7/3/2026
- DeepSeek 联合北大开源 DSpark:半自回归推测解码,推理速度提升 57% 至 85%6/27/2026
- 华为天才少年的开源AI Agent全书:6700星、十章、可跑实验代码7/20/2026
- Cursor 研究:越强的 AI 模型越会"作弊"应对编程基准测试6/26/2026
- Claude Code 被指通过 system prompt 隐蔽传递代理与时区信息6/30/2026
- Qwen-Image-3.0 发布:追求实用的图像生成7/21/2026
- Kimi K3:2.8万亿参数开源模型,前端编程Arena登顶7/17/2026
- Hallmark:一份写给AI编码助手的反AI味设计手册7/17/2026
- Voicebox:43K Stars 的开源 AI 语音工作室,7 引擎 TTS + MCP Agent 集成7/19/2026
- OmniRoute:日增 1300+ Star 的开源 AI 网关,一个端点接通 250 个模型提供商7/20/2026
- 苹果首款触屏 MacBook 确认搭载 M5 Pro/Max,M7 版计划 2027 年跟进6/27/2026
- 27B 模型塞进手机:PrismML Bonsai 27B 把权重压到 1-bit7/18/2026
- 6.4 万 Star 的开源全球情报平台:World Monitor 架构与能力全景7/21/2026
- KTransformers:单 GPU 跑 671B MoE 模型的清华方案7/21/2026
- Qwen3.8 发布:2.4T 参数、原生多模态、开放权重承诺7/19/2026
- GPT-5.6用一段十页提示词,关闭凸优化30年的复杂性缺口7/19/2026
- Claude Record a Skill:录屏一次,永久自动化你的工作流7/22/2026
- jcode:用 Rust 重写的 AI 编码代理,内存占用仅为 Claude Code 的 1/147/22/2026
- AI 代码审查的 token 困境:code-review-graph 如何用代码图谱砍掉 98% 的上下文7/20/2026
- Gemini 3.6 Flash 发布:Token 效率砍 65%,多模态全面领先7/21/2026
- B站在WAIC展出开源AI猫娘:能看懂屏幕、主动搭话的桌面伙伴7/18/2026
- Kimi K3 首登 DeepSWE v1.1:开源权重模型挤进前三7/18/2026
- AI 连破三大数学猜想:Jacobian 猜想 87 年反例与形式化验证的新时代7/21/2026
- 2026 年 AI 都学会了记忆,但你的记忆不属于你7/19/2026
- Moonshine Micro:80美分芯片跑完整语音流水线,500KB内存装下VAD+STT+TTS7/18/2026
- LingBot-Map:用前馈3D基础模型做流式重建,20FPS跑完一万帧7/18/2026