GLM-5.2 追平 Anthropic Mythos 漏洞检测能力,美国 AI 限制政策遭批适得其反
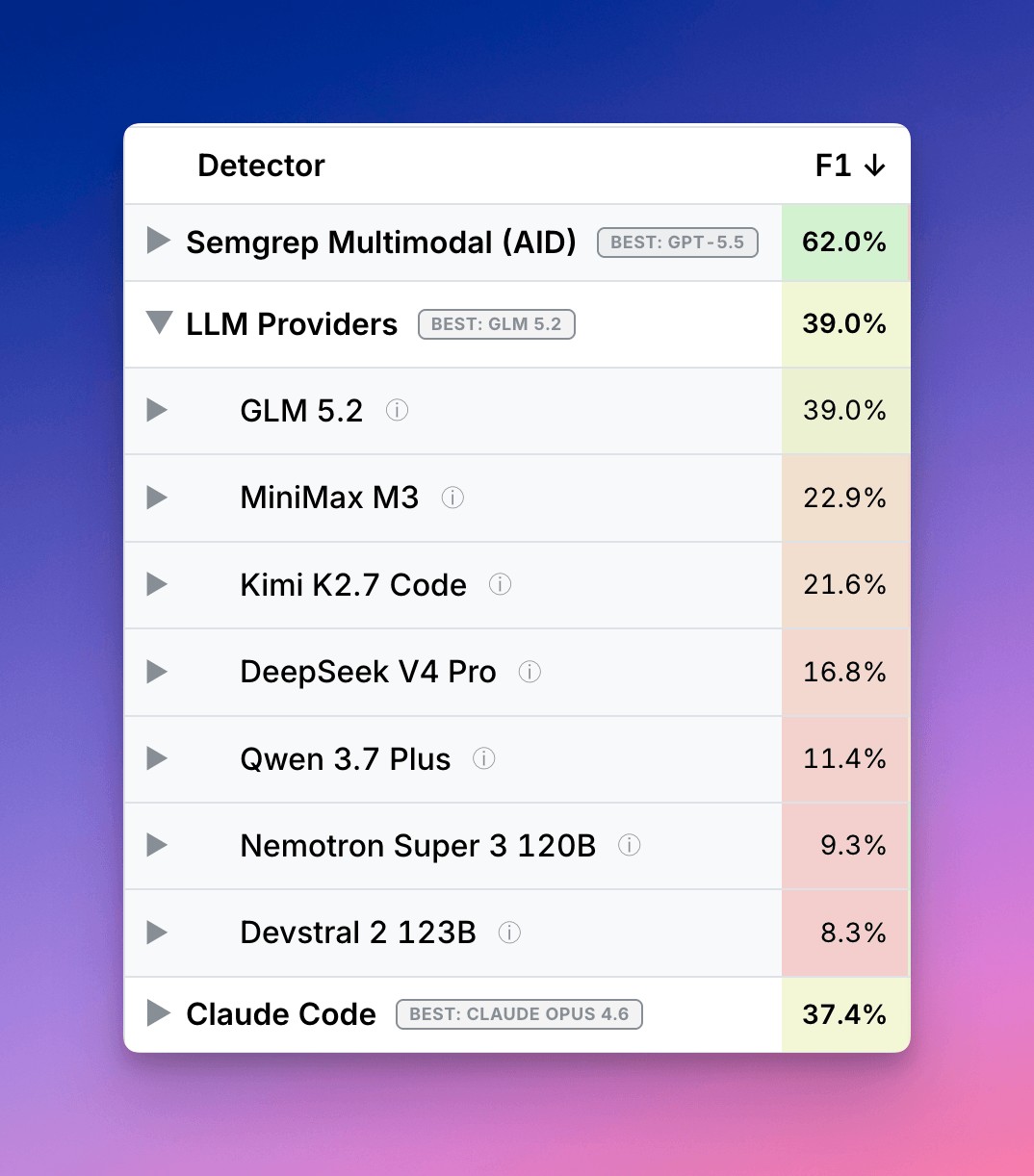
智谱 AI 本月发布的开源模型 GLM-5.2 在软件漏洞检测领域已追平美国顶尖水平。安全公司 Semgrep 的测试显示,GLM-5.2 在 IDOR 检测基准上取得 39% F1,超过 Claude Code(32%),每发现一个漏洞成本仅约 0.17 美元。虽然仍低于 Semgrep 自家的多模态流水线(53-61%),但在仅凭 prompt 驱动的模型中,GLM-5.2 是表现最好的开源权重模型。
GLM-5.2 采用 MoE 架构,总参数约 7500 亿,每个 token 仅激活约 400 亿,推理成本相对可控。它在 Terminal-Bench 2.1 上得分 81.0(Claude Opus 4.8 为 85.0),SWE-bench Pro 上得分 62.1,已跻身全球使用量前列的开源大模型。MIT 许可意味着任何组织都可以下载、运行、微调,在自己的环境中完成安全检测。
360 安全公司在 ISC.AI 2026 大会上发布了号称匹敌 Mythos 的漏洞检测工具“屠龙锋”,标志着中国安全厂商在 AI 驱动防御能力上也在快速追赶。
与此同时,美国政府的 AI 限制政策却在引发反效果。OpenAI 在 6 月 27 日(周五)应美国政府要求,将最新发布的 GPT-5.6 限制为仅对少数“受信合作伙伴”开放预览。Anthropic 此前更惨:6 月 12 日美国政府依据出口管制指令,要求 Anthropic 关闭其最强的网络安全模型 Mythos 5 和通用模型 Fable 5 对所有用户的访问,包括 Anthropic 自身的非美国籍员工。直到 6 月 27 日,商务部才批准 Mythos 5 恢复对约 100 家美国关键基础设施运营机构的部署。Fable 5 至今仍未获批。
批评者指出这种矛盾:封禁美国自身的前沿模型,却在芯片出口政策上留有漏洞,客观上推动了全球企业转向更便宜、更容易获取的中国开源模型。OpenAI CEO Sam Altman 公开表示“不希望政府替企业挑选客户”,认为这种做法会阻碍网络安全防御者获得他们需要的工具。
GLM-5.2 的出现恰好说明了这种政策效果的讽刺性:当美国顶尖模型被层层限制时,中国开源模型正在通过公开的权重和可验证的基准测试,证明自己在关键安全领域能力并不逊色。
- ChatGPT App 的模型切换入口,突然变得很难找3/17/2026
- MiniMax 发布 M2.7:国内首个公开的模型自我进化方案3/18/2026
- 鸿海 Q4 利润不及预期,给 AI 硬件热泼了一盆冷水3/16/2026
- 多地试点一人公司:免费公寓+办公空间,能否激活个体创新?3/19/2026
- 椰树集团相关公司招标 50 台人形机器人剥椰子,产线开始提具体指标了3/19/2026
- Google 把 Stitch 升级成 AI 原生设计画布3/19/2026
- DLSS 5 引发的争议:老黄说批评者完全错误3/19/2026
- 小米三款大模型齐发:MiMo-V2-Pro、Omni、TTS 完整解读3/19/2026
- Hugging Face 最大开源仓库快被 AI 垃圾 PR 淹没了3/19/2026
- 欧盟推去衣AI禁令:3月26日表决,执法难在哪3/19/2026
- iOS 26.4 RC 发布:Apple Music 有 AI 歌单,Podcasts 支持视频3/18/2026
- 小米推理模型 MiMo-V2-Pro 上线:智能指数 49,榜单排第 103/18/2026
- 中国加大对 Meta 收购 Manus 审查:高管限制离境,审查升至国家层面3/18/2026
- OpenAI 发布 GPT-5.4 mini 与 nano:小模型加速冲刺3/17/2026
- 《华盛顿邮报》把 AI 用到订阅定价上,媒体的个性化收费又往前走了一步3/17/2026
- 据报道,微软搁置 Windows 11 多项 Copilot 系统级整合计划3/16/2026
- 据路透:华虹旗下华力微电子拟量产 7 纳米,华虹或成中国第二家 7nm 代工厂3/16/2026
- 爱泼斯坦案幸存者起诉 Google:AI 搜索放大了数据泄露的伤害3/27/2026
- 苹果把 WWDC 2026 定在 6 月 8 日,AI 与开发者工具会是重点3/23/2026
- 英伟达把 DLSS 5 说清楚了:输入只有 2D 帧和运动矢量3/21/2026
- 短视频内容标注,准备进入统一规则阶段3/21/2026
- Google 测试改写搜索结果网页标题,网站对标题的控制权又退了一步3/20/2026
- 营收涨三倍,宇树科技冲刺科创板3/20/2026
- Claude Code 上线 Channels:用 Telegram 和 Discord 操控本地编程任务3/20/2026
- Google AI Studio 升级全栈 vibe coding:Antigravity 代理来了3/20/2026
- 谷歌 Gemini Mac 版内测:桌面端补课正式开始3/20/2026
- Kimi 员工指称 MiniMax 沿用其 Office Skill 代码始末3/19/2026
- OpenAI 收购 Astral:Python 工具链收编加速3/19/2026
- Firefox 149 内置免费 VPN:50GB 月流量,首批限四国3/19/2026
- Anthropic 超 8 万用户调研:81% 认为 AI 正兑现预期3/19/2026