华为韬定律V2深度解读:LogicFolding齿比、Kirin 2026实测与3D堆叠工程化
华为半导体负责人何庭波 7 月 3 日在中国科学院科技论文预发布平台 ChinaXiv 发布《面向多层级电子系统的时间缩微理论》V2 版(业内称"韬定律")。相比 5 月 25 日的 V1 版,V2 补充了大量工程落地细节、实测量化数据与产品演进路线,整合为 8 章完整论述体系。
什么是"韬定律"
韬定律的核心是以时间常数 τ(tau)为标尺,描述多层级电子系统(从晶体管到封装到系统架构)的缩放规律。在摩尔定律逐渐失效的背景下,单纯靠制程微缩获取性能增益越来越困难,韬定律提出了一套替代框架:通过 3D 堆叠、先进封装和逻辑折叠技术,在不缩小晶体管的前提下持续提升系统级性能。
V1 版奠定了理论框架,但缺乏工程验证。V2 版的关键进展在于用华为自己的量产产品(Kirin 2026、Ascend 系列)证明了这套理论的可行性。
LogicFolding 的 gear ratio 概念
V2 版深度阐释了核心技术 LogicFolding 的 gear ratio(齿比)概念。理解齿比需要先理解 3D 堆叠的演进路径。
传统 3D 堆叠(如 TSMC CoWoS、Intel Foveros)按功能块分层:CPU 放一层、缓存放一层、I/O 放一层。这种分层方式粒度粗,只能做"宏块级离散优化"——设计师在有限的功能块组合中挑选最优方案,搜索空间受限。
LogicFolding 的突破在于:当混合键合(hybrid bonding)的间距缩小到接近顶层金属布线尺寸(约 1μm 量级)时,3D 设计空间的粒度从"功能块级"细化到"单元级"。设计师可以在标准单元(standard cell)层面做垂直划分,把同一功能逻辑的单元分散到不同有源层上,实现全局最优的垂直布局。
gear ratio(齿比)就是描述这种垂直划分比例的参数。齿比高意味着更多逻辑被折叠到上层,对层间互连密度的要求更高;齿比低意味着逻辑主要留在底层,上层只放少量高速缓存或 I/O。V2 版给出了不同齿比下的功耗、面积和功率密度权衡曲线。
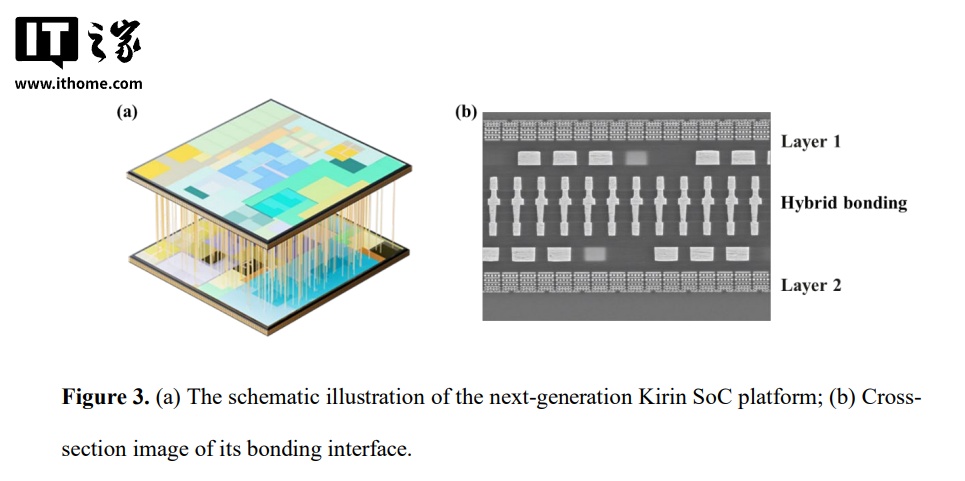
这张图来自 V2 论文 Figure 3。左图是下一代 Kirin SoC 平台的 3D 堆叠架构示意,可以看到两层芯片通过密集的 TSV/混合键合互连垂直堆叠。右图是键合界面的 SEM(扫描电子显微镜)截面照片,显示了铜-铜直接键合的实际物理结构——没有传统的微焊料凸点,而是靠铜原子间的直接扩散实现电气连接,间距在微米级别。
Kirin 2026 实测数据解读
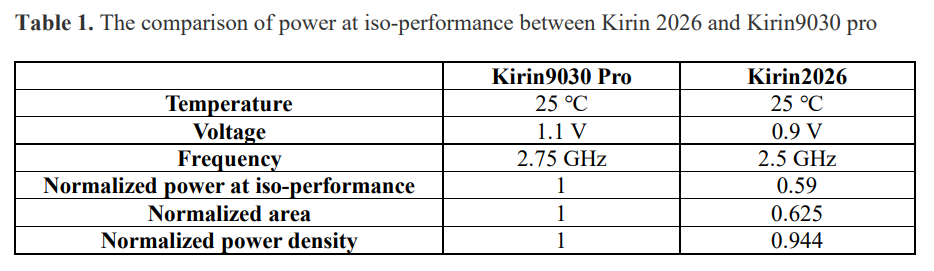
V2 版最引人注目的是 Table 1:Kirin 2026 与基准 Kirin 9030 Pro 的等性能参数对比。
| 参数 | Kirin 9030 Pro | Kirin 2026 | 变化 |
|---|---|---|---|
| 温度 | 25°C | 25°C | 控制变量 |
| 电压 | 1.1V | 0.9V | ↓18.2% |
| 频率 | 2.75GHz | 2.5GHz | ↓9.1% |
| 归一化功耗(等性能) | 1.0 | 0.59 | ↓41% |
| 归一化面积 | 1.0 | 0.625 | ↓37.5% |
| 归一化功率密度 | 1.0 | 0.944 | ↓5.6% |
几个关键解读:
电压从 1.1V 降到 0.9V,这是能效提升的最大驱动力。动态功耗与电压平方成正比(P ∝ CV²f),电压降 18%,理论功耗降幅约 33%。Kirin 2026 实际功耗降了 41%,多出来的 8 个百分点来自面积缩小带来的寄生电容减少和 LogicFolding 优化后的互连线长度缩减。
频率从 2.75GHz 降到 2.5GHz,但标注为"等性能"(iso-performance)。这意味着 Kirin 2026 虽然主频更低,但通过 3D 堆叠缩短了关键信号路径、减少了互连延迟,实际吞吐量与 2.75GHz 的 Kirin 9030 Pro 相当。更低频率对应更低电压,形成正向循环。
面积缩到 62.5%。Kirin 2026 的逻辑面积只有 Kirin 9030 Pro 的约 5/8。这不是单纯靠制程微缩实现的——V2 论文强调这是 LogicFolding 将部分逻辑层折叠到上层后,底层面积得以缩小。结合更先进的制程(推测为台积电 2nm N2),面积效率大幅提升。
功率密度只降了 5.6%。面积缩了 37.5%,功耗降了 41%,两者幅度接近,所以功率密度变化不大。这表明 3D 堆叠并没有导致散热恶化——韬定律 V2 论文中强调的 WMCM(晶圆级多芯片模块)封装和 TSV 下移至 M6 层的设计,确保了热量在更小的面积上仍能有效散出。
TSV 下移至 M6 层
V2 版的移动端路线图补充了一个关键工程细节:TSV(硅通孔)的布线层从顶层金属下移至 M6 层。
在传统 3D 堆叠中,TSV 穿过整个芯片的金属层堆叠,占用大量布线资源。顶层金属层通常用于全局电源分配和关键信号传输,TSV 占据顶层位置会挤压信号布线空间,迫使设计师增加金属层数来补偿。
将 TSV 下移至 M6 层意味着:上层金属(M7-M9 等细线层)可以完全用于信号布线,TSV 只在中下层穿透,对信号完整性的影响更小。这种设计需要精密的对准工艺和更复杂的设计规则检查(DRC),但换来的是更高的布线密度和更优的信号完整性。
V2 版还提到了"多有源层堆叠"的演进方向——将多个有源硅层(不仅是无源互连层)垂直堆叠,每个层都有晶体管。这比当前的"芯片+互连+芯片"模式更进一步,更接近真正的 3D 晶体管架构。
Ascend AI 加速器的迭代节奏
在 AI 端,V2 版明确了 Ascend 系列加速器的迭代节奏。论文没有给出具体产品代号,但路线图显示华为计划将 LogicFolding 技术首先应用于移动端 SoC(Kirin 系列),再扩展到 AI 加速器(Ascend 系列)。
AI 加速器对 3D 堆叠的需求比移动 SoC 更迫切。大模型推理需要海量高带宽内存(HBM),而 LogicFolding 可以将计算单元和内存缓存层垂直堆叠,减少数据搬运的能耗和延迟。V2 论文的 τ 分层时空模型也为此提供了理论框架——不同层的 τ 值对应不同的热时间常数和电气时间常数,指导多层级协同设计。
V2 新增的可视化内容
V2 版新增了多张原理与实物示意图,覆盖核心技术:
- τ 分层时空模型:展示从晶体管级到系统级的时间常数分布
- LogicFolding 架构:齿比参数的可视化表示
- 键合界面截面:混合键合的 SEM 照片
- Unified Bus 互连架构:层间高速总线设计
- Hi-ONE 光引擎:华为自研的光互连方案
这些示意图和实测数据在 V1 版中均未出现,V2 版的工程成熟度明显高于 V1。
行业定位
韬定律的发布时间点值得关注。2026 年全球先进封装产能紧张,台积电的 CoWoS 和 SoIC 供不应求。华为作为中国最大的芯片设计公司之一,在先进封装领域的技术积累直接关系到其能否绕过制程限制。
V2 论文通过 Kirin 2026 的实测数据,试图证明 LogicFolding 路线的工程可行性。功耗降 41%、面积缩 37.5% 的数据如果经第三方验证,意味着华为在 3D 堆叠领域已具备与国际一流代工厂(台积电、三星)竞争的技术基础。
来源:IT之家
- 据路透:华虹旗下华力微电子拟量产 7 纳米,华虹或成中国第二家 7nm 代工厂3/16/2026
- 苹果美国制造计划再扩 4 家,传感器和半导体工艺产线往回拉3/27/2026
- 特斯拉适配鸿蒙:一个操作系统的成人礼4/7/2026
- 华为发表韬(τ)定律:以时间缩微替代几何缩微5/25/2026
- Anthropic 洽谈由三星代工自研 AI 芯片7/2/2026
- Mate 80 Pro Max 风驰版开启预定:主动散热旗舰来了3/20/2026
- 华为预计今年 AI 芯片营收达 120 亿美元,同比增长逾 60%5/1/2026
- 黄仁勋:英伟达已基本放弃中国AI芯片市场5/21/2026
- 字节跳动、阿里巴巴拟采购华为新款 AI 芯片 950PR3/27/2026
- 华为把 Atlas 350 推到了商用节点3/21/2026
- 苹果与英特尔、三星初步探讨在美生产设备处理器5/5/2026
- 三星终止 LPDDR4/4X 接单,全面转向先进制程4/17/2026
- 华为开源 920 亿参数 openPangu-2.0-Flash 模型6/30/2026
- 大基金据称洽谈领投DeepSeek首轮融资,估值约450亿美元5/6/2026
- 中国半导体设备营收创纪录,美系设备绕道东南亚涌入4/17/2026
- 三星电子市值突破1万亿美元,韩国KOSPI指数首破7000点5/6/2026
- 王云鹤离职:华为诺亚方舟实验室两年换两帅3/28/2026
- FCC 拟全面封堵中国企业设备进口4/4/2026
- Apple 与 Intel 达成初步芯片代工协议,Intel 股价飙升 18%5/8/2026
- 华为发表韬定律:换了一把量芯片的尺子5/27/2026
- 无锡建Token工厂:1536卡昇腾超级集群落地5/17/2026
- 台积电称 ASML High-NA EUV 太贵,2029 年前暂不导入量产4/23/2026