NVIDIA 软件优化将 DeepSeek V4 Token 成本降至五分之一
NVIDIA 在 Blackwell 平台上持续优化推理软件栈,一个月内将 DeepSeek V4 的 Token 生成成本降至原先的五分之一。
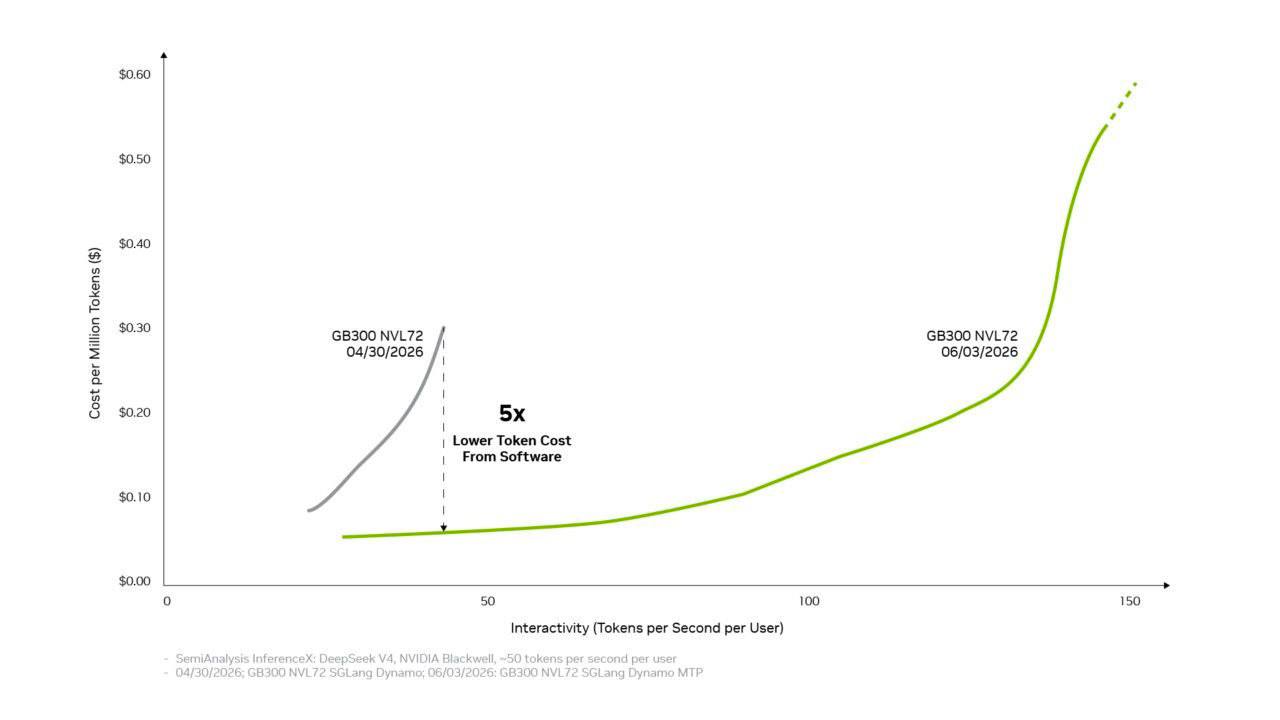
PyTorch 社区发布的基准数据显示,在 GB300 NVL72 离散式部署下,SGLang 引擎的吞吐量从 4 月初(Day-0)的约 2,200 Tokens/秒/GPU 提升至 6 月的约 11,200 Tokens/秒/GPU。在保持用户约 50 Tokens/秒的高流畅交互体验下,性能提升 5 倍,单 Token 成本降至约 $0.156/百万输出 Token(8K 输入 / 1K 输出配置)。
优化手段
性能提升来自多项内核与运行时的深度优化协同:
- MHC 融合与 token-bucket 预热:减少计算图中断
- KV Cache 压缩 V2:更高效的显存利用
- W4A4 MegaMoE:FP4 精度下的 MoE 融合分发,替代逐专家内核调度
- 增强 SWA 预算与驱逐策略:改善显存分配效率
- 可中断 CUDA Graph:在 DeepSeek V4 prefill 路径中支持计算图中断
- 离散式解码拓扑重写:从 EP=8 拓宽到 EP=16,prefill worker 从 1-2 个扩展到 4-12 个,并发上限提升至 21,504
这些优化覆盖了 SGLang 和 vLLM 两个主流推理框架,且在 Day-0 发布时就已有可用配方。
Blackwell Ultra 聚合部署
Blackwell Ultra 聚合方案也获得了显著提升:no-MTP 在 30 tok/s/user 下提升 2.91x,MTP 在 90 tok/s/user 下提升 2.85x。no-MTP 峰值吞吐相比 Day-0 提升超过 6 倍,原因是配方从低效的 TP-only 执行升级到包含 DP attention 和更宽搜索空间的成熟 FP4/MoE 路径。
进一步优化空间
NVIDIA 表示,在当前优化基础上叠加分解式服务、新浮点精度和多 Token 预测(MTP)等高级优化后,系统级吞吐量最高有望提升至 20 倍。Baseten、Cognition、Deep Infra 和 Together AI 等推理服务商已在生产环境中采用该软件栈。
相关推荐
- DLSS 5 引发的争议:老黄说批评者完全错误3/19/2026
- CAISI 评估 DeepSeek V4 Pro:综合能力落后美国前沿约 8 个月5/3/2026
- NVIDIA N1X Arm 笔记本芯片深度解析:20 核 CPU + 6144 CUDA 核 GPU,Computex 即将改写 PC 格局5/30/2026
- 英伟达发布全球首个开源量子 AI 模型家族 Ising,用 AI 打造量子计算机的「操作系统」4/15/2026
- DeepSeek V4 即将发布:万亿参数、百万上下文、全面适配国产芯片4/10/2026
- DeepSeek 开源 TileKernels:面向 Blackwell 架构的高性能 LLM 算子库4/23/2026
- DeepSeek 发布视觉基元推理报告,用点和框解决多模态 Reference Gap4/30/2026
- 乐天开放 Rakuten AI 3.0:日语成绩单很亮眼,DeepSeek V3 架构标签也把争议一起带了出来3/17/2026
- 京东上线AI硬件自营专区,多款受制裁NVIDIA GPU恢复公开售卖5/14/2026
- 英伟达 NTC 纹理压缩:显存降 85%,画质近乎无损4/5/2026
- DeepSeek发布DeepGEMM重大更新:MegaMoE融合算子与FP4精度支持4/16/2026
- NVIDIA DLSS 4.5 Ray Reconstruction 8 月上线,覆盖全系 RTX 显卡6/1/2026
- 黄仁勋公开批评 Amodei、Musk 等人的 AI 末日预言5/4/2026
- 大基金据称洽谈领投DeepSeek首轮融资,估值约450亿美元5/6/2026
- DeepSeek-V4 正式上线:1M 上下文标配,Flash 输入 0.2 元/百万 token4/24/2026
- NVIDIA Nemotron 3 Nano Omni:一个开放模型统一视觉、音频和语言4/29/2026
- Google 每月付 SpaceX 9.2 亿美元租 AI 算力,协议至 2029 年6/6/2026
- 黄仁勋称 AI 将创造大量就业并助力美国再工业化5/5/2026
- NVIDIA RTX Spark 发布:128GB 统一内存的 AI PC 超级芯片6/1/2026
- NVIDIA 与 OpenAI 联合发布 MRC 协议,提升 AI 超算集群效率5/6/2026
- 腾讯阿里据报洽谈投资 DeepSeek,估值超 200 亿美元4/22/2026
- DeepSeek V4 正式定价公布:Pro 限时 2.5 折,Flash 输入低至 0.2 元/百万 token4/25/2026
- DeepSeek 拟融资超 500 亿,6 月将发布 V4.1 更新5/8/2026
- DeepSeek 拟以 100 亿美元估值融资至少 3 亿美元4/17/2026
- 黄仁勋站台 Marvell:AI 的下一关是连接6/2/2026
- DeepSeek 将 V4-Pro 模型 2.5 折优惠延长至 5 月底4/28/2026
- 斯坦福2026 AI指数报告:中美AI性能差距仅剩2.7%4/14/2026
- DeepSeek 联合北大开源 DSpark:半自回归推测解码,推理速度提升 57% 至 85%6/27/2026
- DeepSeek 大规模宕机超 12 小时:基础设施与用户增长的裂缝3/30/2026
- 英伟达在中国重新上架RTX 3060 12GB显卡6/2/2026