字节跳动 Seed3D 2.0:从图像到可仿真 3D 内容的两阶段生成
字节跳动 Seed 团队正式发布新一代 3D 生成大模型 Seed3D 2.0,核心目标是将 3D 内容生成从演示级推进到生产可用。技术报告已公开,API 已上线火山引擎。
几何生成:两阶段 DiT 解耦结构
Seed3D 1.0 需要同时完成"整体结构"和"精细结构"的生成,容易在锐利边缘和精细结构上出现"软化"现象。Seed3D 2.0 引入 Coarse-to-Fine 两阶段生成策略,将两者解耦优化:
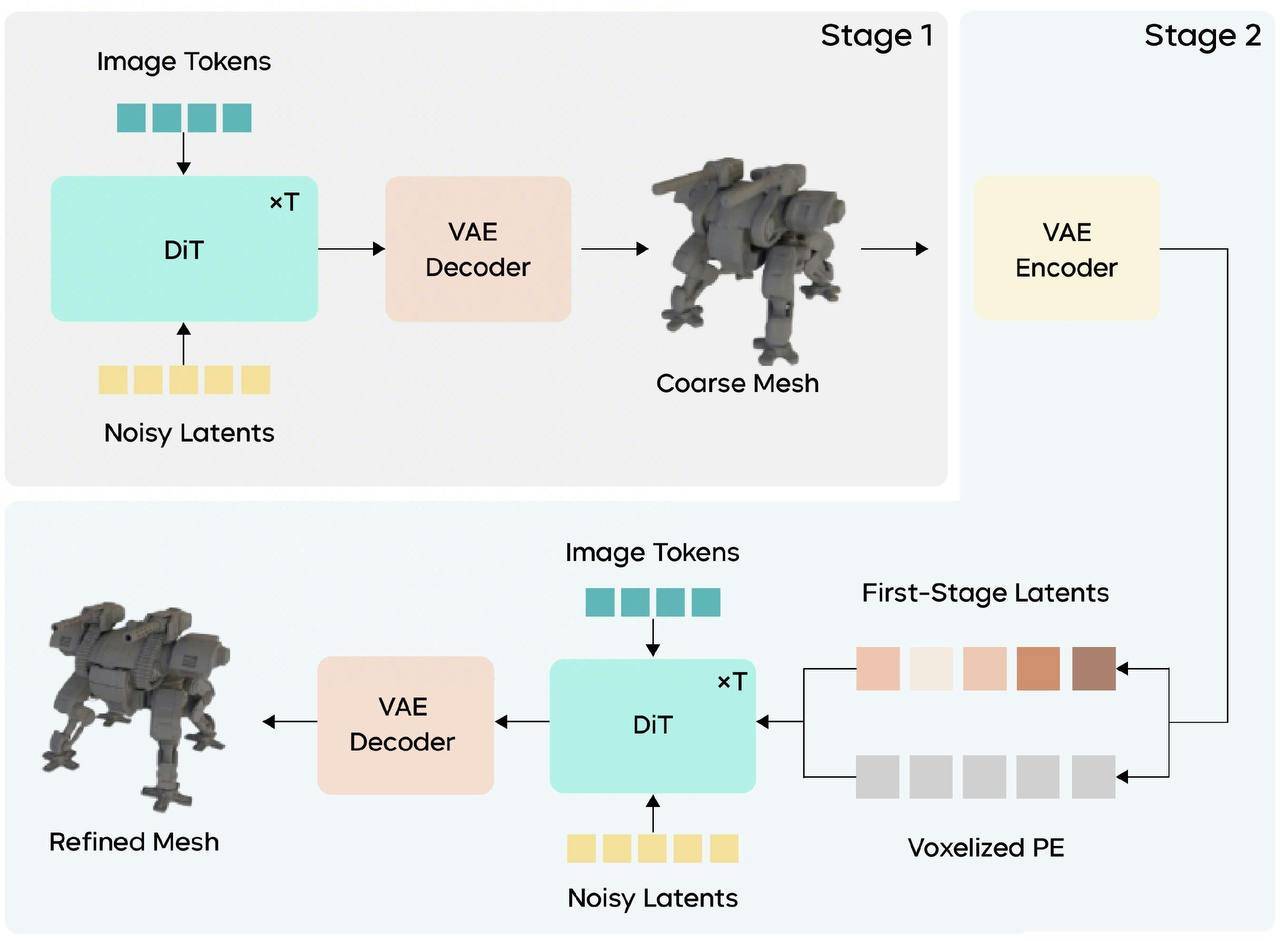
阶段一:使用更大参数规模的 DiT,基于输入图像生成粗粒度几何结构,建立整体拓扑关系和空间布局。
阶段二:以阶段一输出为几何锚点,专注于锐利边缘、精细表面等细节恢复。引入两种关键先验:
- 局部感知先验:将第一阶段的粗糙结果转化为隐变量,为细节生成提供可靠的初始化输入
- 体素化位置编码(Voxelized PE):在第一阶段生成的几何表面采点并体素化,作为位置编码提供空间位置约束
VAE 侧也做了同步升级,更少的 token 即可获得更高的重建精度,并支持根据内容动态分配注意力。
在 60 位具有 3D 建模经验的人类打分员、约 200 个测试用例的两两盲评中,Seed3D 2.0 在几何形状生成维度相比所有主流模型呈现更高的偏好率。
纹理生成:统一 PBR 模型
Seed3D 1.0 采用级联式模型进行 RGB 生成和 PBR 分解,中间步骤误差会逐级累积。Seed3D 2.0 改为统一的 PBR 生成模型,保持 MMDiT 双流架构,通过模态特定投影层在共享 DiT 层中联合建模完整 PBR 贴图。
两项关键创新:
1. MoE 架构提升高分辨率材质精度 通过稀疏专家路由,在扩大参数量和分辨率的同时控制推理计算量,解决了材质分解中细节丢失的问题,金属-粗糙度边界更加精确。
2. VLM 先验增强材质分解稳定性 从 RGB 图像逆向推导 PBR 材质是行业难题——相同外观可能由不同材质与光照组合产生。引入 VLM 对输入图片的材质类型和物理属性进行描述,作为额外控制信号注入 DiT,有效减少了色偏和金属性误判。
在纹理生成人类评测中,Seed3D 2.0 面对主流模型的偏好率超过 69%。
下游能力:部件级生成与关节化建模
Seed3D 2.0 将能力从单一物体生成扩展到部件级操作和场景组合:
部件分割与补全
采用"先理解,再生成"范式。通过训练的 Seed3D-PartSeg 3D 理解模块对完整 3D 网格进行表面分割,再由 Seed3D-PartDiT 以全局 3D 形状、分割点云和图像为输入,补全每个部件的完整形状。
一把椅子会被自动拆分为座椅、靠背和底座;机器人按四肢等部位精细拆解。
关节化建模
在部件分割基础上,利用 VLM 将部件拆分为运动学组件并识别关节类型(如"可旋转部件"或"固定结构"),结合几何先验估计关节轴位置。引入图生视频模型生成运动参考以优化关节运动范围。
最终输出带有完整关节信息、以 URDF 等标准格式呈现的 3D 内容,兼容 Isaac Sim 等主流物理仿真引擎。
场景生成
对于文本输入,利用微调过的 LLM 进行空间关系推理和布局生成;对于多视角图片或视频输入,利用深度估计、实例分割和遮挡修复等能力推理场景空间布局。最终逐个生成 3D 内容并按空间关系组合,构建完整场景。
意义
Seed3D 2.0 的进步意义不仅在于指标提升,更在于它瞄准了一个关键问题:3D 生成如何从"看起来像"变成"用得上"。
几何精度的提升(锐利边缘、薄壁结构、复杂拓扑)和 PBR 材质的统一生成(任意光照下物理一致的视觉效果)解决了"质量"问题;部件级生成、关节化建模和 URDF 输出解决了"下游适配"问题——这意味着生成的 3D 内容可以直接导入仿真环境进行物理交互测试,不再只是一个好看的三维模型。
对于具身智能和机器人领域,这意味着从图像到可仿真物体的 pipeline 大幅缩短。
局限与挑战
官方也坦诚了当前局限:
- 几何生成精细度与泛化性仍需提升
- 纹理生成存在遮挡与贴图误差
- 推理效率仍是大规模应用的瓶颈
- 落地场景仍在探索中
体验入口:火山方舟体验中心 → 视觉模型 → 3D 生成 → Doubao-Seed3D-2.0
- LingBot-Video技术解读:全球首个MoE具身视频基模7/9/2026
- 字节跳动开源 Lance:3B 参数统一图像视频理解生成与编辑5/22/2026
- 字节 Seed 2.1 Pro Preview 杀入 Code Arena 前端前十6/22/2026
- 豆包计划推出三档付费订阅服务5/4/2026
- 阿里腾讯同日发布3D世界模型:从生成视频到造世界4/16/2026
- 豆包输入法闲置时的后台网络行为:那些不该出现的域名4/4/2026
- 字节跳动发布 Seeduplex:全双工语音模型在豆包全面上线4/9/2026
- 字节跳动 Seedance 2.0 出海:AI 视频生成加了一道版权护城河3/27/2026
- 美国两党参议员要求字节立即关闭 Seedance 2.0:AI 视频版权冲突进入产品治理阶段3/17/2026