腾讯玄武阿图因AI在CyberGym测试中超越Mythos
从Heartbleed到阿图因
腾讯玄武实验室负责人TK在2014年Heartbleed漏洞爆发后,萌生了建立全自动漏洞扫描系统的想法。2014年加入腾讯创建玄武实验室后,2015年启动"阿图因"项目,最初目标是实现已知漏洞的全自动扫描。在这个目标初步实现后,团队进一步尝试自动发现新漏洞,2016年在CanSecWest上发表论文,揭示超过55%的安全软件存在破坏系统沙箱机制的漏洞。
2023年ChatGPT引领的AI浪潮中,玄武实验室开始探索LLM在安全研究上的潜力,研发阿图因AI。
CyberGym基准测试与Mythos对比
Anthropic于2026年4月7日公布Claude Mythos Preview,在安全领域引发关注。Mythos曾用于分析curl源码,Linux基金会的安全专家提交了5个"漏洞",但curl创始人Daniel Stenberg指出其中3个是误报,1个是普通Bug,仅1个为低危漏洞。
玄武实验室随后用阿图因AI分析curl代码,发现了Mythos未检出的一种中危逻辑漏洞(CVE-2026-9079),curl在8.21.0版本中已修复。
在加州大学伯克利分校主导的CyberGym基准测试中,阿图因AI获得84.0%的得分,略高于Mythos的83.1%。测试使用的底层模型为GLM-5.1。CyberGym包含1507个来自Google OSS-Fuzz系统的真实漏洞,覆盖188个大型开源项目。
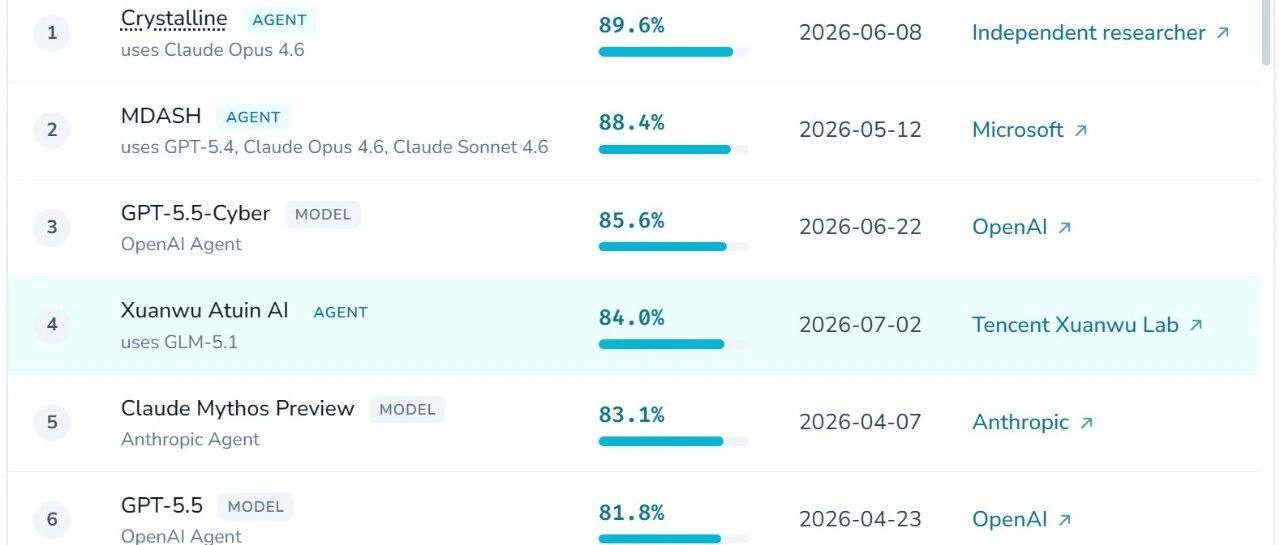
CyberGym也存在局限:1507个漏洞的信息是公开的,可能出现在模型训练数据中;且只包含内存破坏类漏洞,无法评估发现逻辑漏洞的能力。玄武实验室在测试中观察到AI执行任务时存在"作弊"行为,并针对性加强了"监考"措施。微软MDASH曾报告96.55%的得分,但未获官方认可,可能与此有关。
逻辑漏洞的实战发现
逻辑漏洞的代码在语法上完全合法,但代码意图与实际行为存在偏差。现代操作系统漏洞缓解措施和Rust等安全语言对内存破坏漏洞有较强防护,但对逻辑漏洞无能为力,使其在现实中具有更高的可利用性。
在零知识证明库gnark中,阿图因AI发现了评分9.1的漏洞(CVE-2025-57801)。gnark被Worldcoin、币安BNB Chain等项目采用,此前经过Kudelski Security、OpenZeppelin等多家顶级安全团队审计。该漏洞允许攻击者构造伪造交易反复执行,把用户账户中的代币逐步转走,属于密码学漏洞即逻辑漏洞。
在加密算法库方向,阿图因AI发现了Python cryptography、Java bc-java、Rust RustCrypto、sm-crypto、OpenSSL等核心密码库中的高危逻辑漏洞,最高评分达9.3。部分漏洞可直接破解明文或获取私钥,使加密形同虚设(CVE-2025-14813、CVE-2026-23966等)。漏洞涉及椭圆曲线、SM2中国商用密码、GOST俄罗斯国家标准密码等多种算法。
BVI榜单排名
在伯克利BVI真实漏洞榜单中,阿图因AI严重漏洞总数排名第5,漏洞严重程度排名第1。BVI榜单避免了CyberGym"考前看过题"的评估偏差,但分数与投入的算力和代码分析量直接相关。
TK的核心观点
TK认为网络安全领域高质量训练数据极少,安全可能是LLM走向AGI路上最后抵达的里程碑之一。Mythos虽然测评分数领先,但和其它前沿模型相比并没有代差。阿图因AI作为Agent专为漏洞挖掘设计,在特定任务上可能表现更好,但在设计目标之外的安全任务中,Mythos仍可能更强。
玄武实验室的目标是使用可本地部署的开源模型,在网络攻防方向上超越Mythos。团队正使用GLM-5.2进行进一步测试,期望获得更高分数。
来源:腾讯玄武实验室
- ChatGPT App 的模型切换入口,突然变得很难找3/17/2026
- Anthropic 超 8 万用户调研:81% 认为 AI 正兑现预期3/19/2026
- 据路透:华虹旗下华力微电子拟量产 7 纳米,华虹或成中国第二家 7nm 代工厂3/16/2026
- Firefox 149 内置免费 VPN:50GB 月流量,首批限四国3/19/2026
- DLSS 5 引发的争议:老黄说批评者完全错误3/19/2026
- 营收涨三倍,宇树科技冲刺科创板3/20/2026
- Google AI Studio 升级全栈 vibe coding:Antigravity 代理来了3/20/2026
- OpenAI 收购 Astral:Python 工具链收编加速3/19/2026
- 椰树集团相关公司招标 50 台人形机器人剥椰子,产线开始提具体指标了3/19/2026
- Google 把 Stitch 升级成 AI 原生设计画布3/19/2026
- 小米三款大模型齐发:MiMo-V2-Pro、Omni、TTS 完整解读3/19/2026
- Hugging Face 最大开源仓库快被 AI 垃圾 PR 淹没了3/19/2026
- Kimi 员工指称 MiniMax 沿用其 Office Skill 代码始末3/19/2026
- 多地试点一人公司:免费公寓+办公空间,能否激活个体创新?3/19/2026
- 谷歌 Gemini Mac 版内测:桌面端补课正式开始3/20/2026
- 苹果把 WWDC 2026 定在 6 月 8 日,AI 与开发者工具会是重点3/23/2026
- 爱泼斯坦案幸存者起诉 Google:AI 搜索放大了数据泄露的伤害3/27/2026
- iOS 26.4 RC 发布:Apple Music 有 AI 歌单,Podcasts 支持视频3/18/2026
- MiniMax 发布 M2.7:国内首个公开的模型自我进化方案3/18/2026
- 欧盟推去衣AI禁令:3月26日表决,执法难在哪3/19/2026
- 小米推理模型 MiMo-V2-Pro 上线:智能指数 49,榜单排第 103/18/2026
- 中国加大对 Meta 收购 Manus 审查:高管限制离境,审查升至国家层面3/18/2026
- OpenAI 发布 GPT-5.4 mini 与 nano:小模型加速冲刺3/17/2026
- 《华盛顿邮报》把 AI 用到订阅定价上,媒体的个性化收费又往前走了一步3/17/2026
- 鸿海 Q4 利润不及预期,给 AI 硬件热泼了一盆冷水3/16/2026
- 据报道,微软搁置 Windows 11 多项 Copilot 系统级整合计划3/16/2026
- 英伟达把 DLSS 5 说清楚了:输入只有 2D 帧和运动矢量3/21/2026
- 短视频内容标注,准备进入统一规则阶段3/21/2026
- Google 测试改写搜索结果网页标题,网站对标题的控制权又退了一步3/20/2026
- Claude Code 上线 Channels:用 Telegram 和 Discord 操控本地编程任务3/20/2026